InceptionNet: Google's comeback for ImageNet Challenge


The 2014 winner of the ImageNet challenge was the InceptionNet or GoogLeNet architecture from Google. The most straightforward way of improving the performance of deep neural networks is by increasing their size: depth (the number of layers) and width (the number of units at each layer).
But with such a big network comes a large number of parameters (which makes it prone to overfitting) and increased use of computation resources. In order to cater to these problems, the design choices of GoogLeNet were focused on efficiency.
Architecture: In order to very aggressively downsample the spatial dimensions of the input image at the beginning, GoogLeNet uses a Stem Network. This looks very similar to AlexNet or ZFNet (and local response normalization is used in this network).

It then includes an Inception module, a local structure with parallel branches that was repeated many times throughout the entire network (just like stages in VGGNet). In order to eliminate the kernel size as a hyperparameter, the input is passed through all the kernel sizes: $1 \times 1$, $3 \times 3$, $5 \times 5$ and max-pooling $3 \times 3$ with a stride of 1 and the outputs are concatenated together. ReLU is used as an activation function here.
This enables the network to learn various spatial patterns at different scales as a result of the varying conv filter sizes. The design follows the practical intuition that visual information should be processed at various scales and then aggregated so that the next stage can abstract features from the different scales simultaneously.
 |
| Naive Inception Module |
One big problem with such modules is that performing convolutions can be prohibitively expensive when the input has many channels. From the above image, let's take the example of 32 $5 \times 5$ conv filters which are applied over the $28 \times 28 \times 192$ input.
The number of multiplications: \begin{equation*} 5 \times 5 \times 32 * 28 \times 28 \times 192 = 120422400 \approx 120 \text{M} \end{equation*}
This problem becomes even more pronounced once pooling units are added to the mix: the number of output filters equals the number of filters in the previous stage (as pooling layers do not reduce the number of channels). The merging of the output of the pooling layer with outputs of the conv layers would lead to an inevitable increase in the number of outputs from stage to stage, leading to a computational blow-up within a few stages.
To solve this problem, a $1 \times 1$ bottleneck layer is introduced to reduce channel dimensions before performing expensive spatial convolutions. Not only is it used to compute reductions, but it also introduces extra non-linearity (as they are followed by ReLU).
 |
| Inception module with dimensionality reduction |
The bottleneck layer is implemented before the convolutions so that the computation takes place on a reduced number of channels, giving rise to reduced computation. It also included after the maxpool layer to control the number of output channels.
The number of multiplications: \begin{align*} & (1 \times 1 \times 16 * 28 \times 28 \times 192) + (5 \times 5 \times 32 * 28 \times 28 \times 16) \\ &= 2408448 + 10035200 \\ &= 12443648 \approx 12M. \end{align*}
The computation cost of a component within the Inception Module(12M) is ten times smaller than a Naive Inception Module(120M). Such a technique allows for increasing the number of layers significantly without an uncontrolled blow-up in computational complexity at later stages.
The previous models used to flatten the output from the last conv layer, and pass it through the fully-connected layers to collapse the spatial dimensions. However, FC layers have a lot of parameters that increase memory usage. GoogLeNet instead uses global average pooling with a kernel size of $7 \times 7$, followed by one single linear layer (with softmax) to generate class scores.
Removing FC layers means we cannot add dropout layers anymore. Given the relatively large depth of the network, the ability to propagate gradients back through all the layers became a problem. The authors had to add auxiliary classifiers at two intermediate stages to combat the vanishing gradient problem while providing regularization.
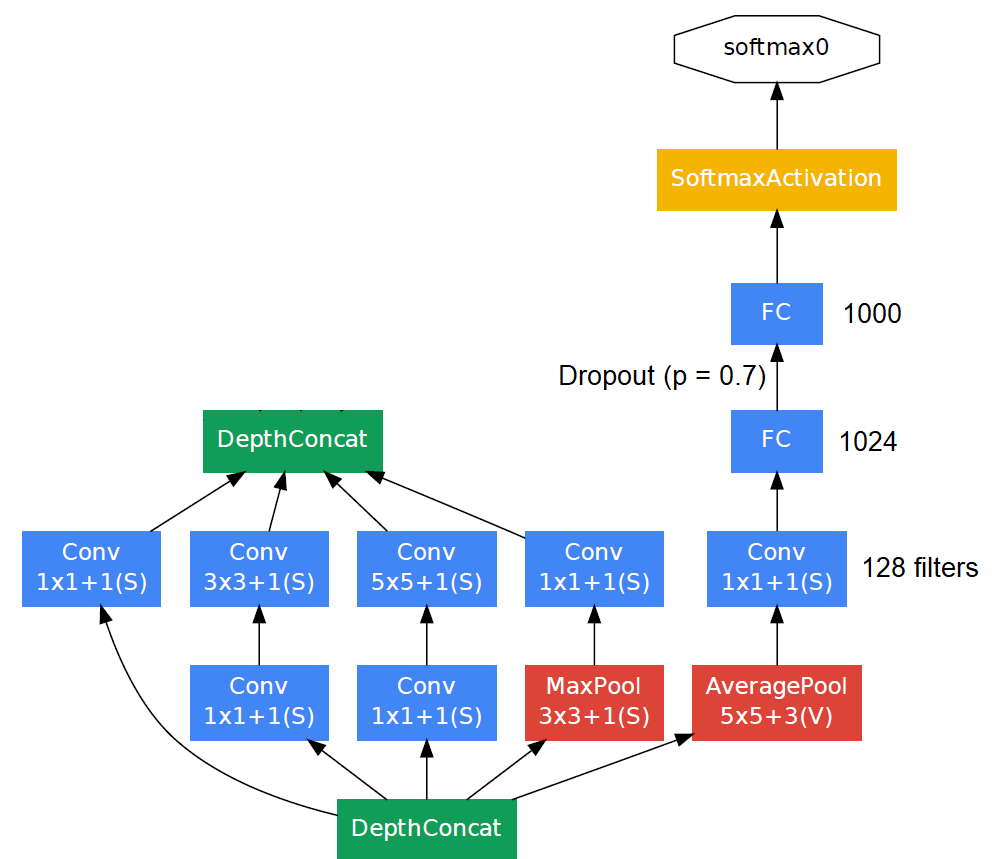 |
| Auxillary Classifier |
During training, their loss gets added to the total loss of the network with a discount weight (the losses of the auxiliary classifiers were weighted by 0.3). At inference time, these auxiliary networks are discarded.
The full 22-layer GoogLeNet architecture is shown below.

Training: The model was trained on the Cross-entropy loss function using stochastic gradient descent with a momentum of 0.9. A fixed learning rate schedule was used, where it was decreased by 4% every 8 epochs. (No other information about training is given in the paper)
Link to the paper: Going Deeper with Convolutions
Trivia: The name Inception probably sounds familiar, especially if you are a fan of the actor Leonardo DiCaprio or movie director, Christopher Nolan. Inception is a movie released in 2010, and the concepts of the embedded dream state (dreams within dreams) were the central premise of the film. This idea turned into a popular internet meme, which the authors cite as an inspiration for the name chosen for the architecture (as it is a network within a network).

The team also chose the name "GoogLeNet" as their team name in the ILSVRC14 competition, paying homage to Yann LeCuns pioneering LeNet 5 network (the earliest network that introduced convolutions)



Comments
Post a Comment