Probabilistic Movement Primitives Part 4: Conditioning

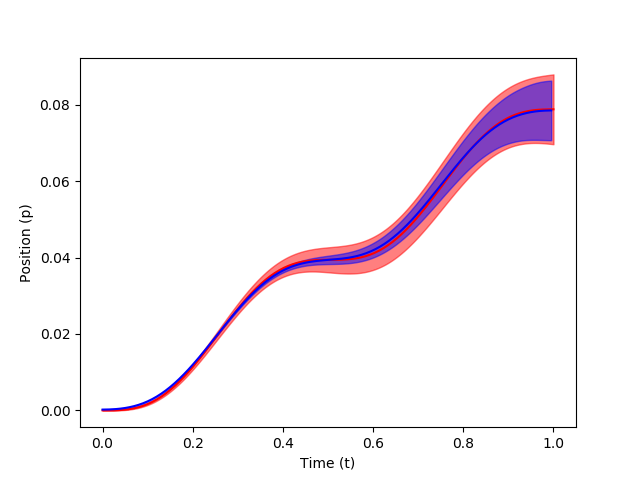
The modulation of via-points, final positions, and velocities is carried out using conditioning so that MP can adapt to new situations. In order to condition the MP to reach a certain state $y^*$ at any time point $t$, a desired observation $x^*_t = [y_t^*, \Sigma_y^*]$ is added to the model. Applying Bayes theorem, \begin{equation} p(w|x^*_t) \propto \mathcal{N} (y^*_t | \Psi_t w, \Sigma^*_y) \; p(w) \end{equation} where state vector $y^*_t$ defines the desired position and velocity at a time $t$ and $\Sigma_y^*$ defines the accuracy of the desired observation. The conditional distribution $p(w|x^*_t)$ is Gaussian for a Gaussian trajectory distribution, whose mean and variance are given by, \begin{equation} \mu_w^{[new]} = \mu_w + L (y_t^* - \Psi_t^T \mu_w), \hspace{10mm} \Sigma_w^{[new]} = \Sigma_w - L \Psi_t^T \Sigma_w, \end{equation} where $L = \Sigma_w \Psi_t {(\Sigma_y^* + \Psi_t^T \Sigma_w \Psi_t)}^{-1}$. Let's code via_points = [(0.2, .02),...