Probabilistic Movement Primitives Part 3: Supervised Learning
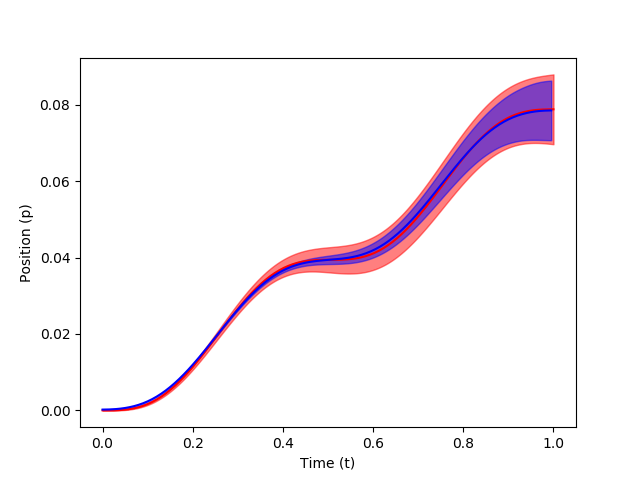
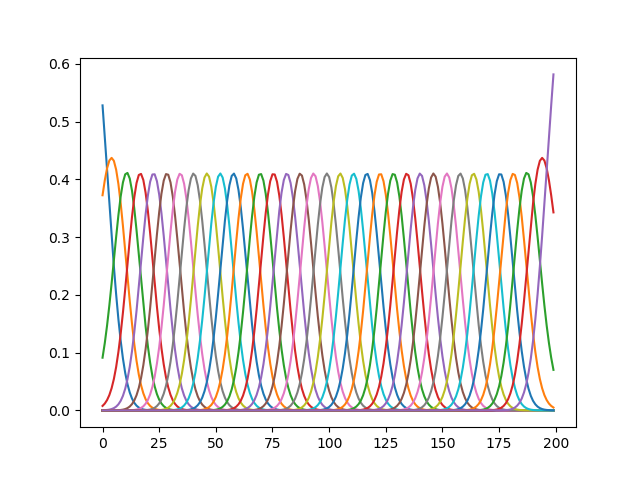
In this post, we describe how a Probabilistic Movement Primitive can be learnt from demonstrations using supervised learning. Learning from Demonstrations To simplify the learning of the parameters $\theta$, a Gaussian is assumed for $p(w; \theta) = \mathcal{N}(w | \mu_w, \Sigma_w)$ over $w$. The distribution $p(y_t| \theta)$ for time step $t$ is written as, \begin{equation} \begin{aligned} p(y_t| \theta) & = \int p(y_t| w) \; p(w; \theta) dw, \\ & = \int \mathcal{N}(y_t | \Phi_t w, \Sigma_y) \; \mathcal{N}(w | \mu_w, \Sigma_w), \\ & = \mathcal{N}(y_t | \Phi_t \mu_w, \Psi_t \Sigma_w \Phi_t^T + \Sigma_y). \end{aligned} \end{equation} It can be observed from the above equation, that the learnt ProMP distribution is Gaussian with, \begin{equation} \mu_t = \Phi_t \mu_w, \hspace{10mm} \Sigma_t = \Phi_t \Sigma_w \Phi_t^T + \Sigma_y \end{equation} Learning Stroke-based Movements For stroke-based movements, the parameter $\theta = \{ \m...