Markov Decision Processes Part 3: Bellman Equations and Optimal Policy
Since two posts we have been talking about MDPs. As discussed in the previous post, the ultimate goal of a MDP is to maximize the total future reward. In the last post, we had calculated the cumulative sum of the long-term rewards (Gt). In this post, we will calculate the expected long-term reward which the agent has to maximize.
A value of a state is the total amount of reward an agent can expect to accumulate over the future, starting from that state. A value function computes the value of a state. A value of state gives us an estimate of how good the state is to be in. The value of a state should not be confused with rewards. A reward signal indicates what is good in an immediate sense, whereas a value function specifies what is good in the long run. For example, a state might always yield a low immediate reward but still have a high value because it is regularly followed by other states that yield high rewards. Since our goal is to maximise long-term reward, we take into account the value function. We then seek actions that bring about states of the highest value, not the highest reward because these actions obtain the greatest amount of reward for us over the long run. The value function vπ of a state s under a policy π is given by,
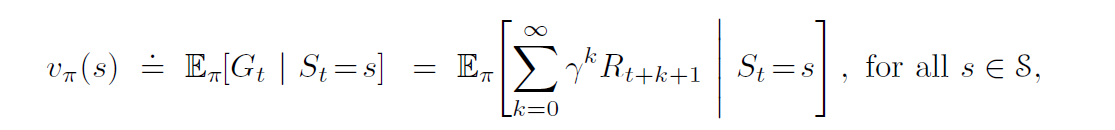
Note that the value of Gt is same as the one computed in the previous post and we are simply written down an expression for its expected value. In order to solve this, we use the Bellman equation,

As discussed earlier, the value of a state determines how good is a state for an agent to be in. An optimal policy is the one which maximizes the total sum of rewards. Therefore, an optimal policy would always suggest an action in a particular state in the direction of increasing value. For example if an agent is in a state s with a value 0.51 and an action up will result in state s1 (value = 0.2), action down will result in state s2 (value = 0.31), action left will result in state s3 (value = 0.7) and action right will result in state 4 (value = 0.36); an optimal policy would always suggest the action left. An optimal policy would always drive an agent towards the increasing value of a state. The state value function for an optimal policy can be computed using,

Similarly, we can also define the value of taking an action a in the state s under the policy π using an action-value function. An action-value function computes the expected reward an agent would gain in the long term after executing action a in the state s. It is given by,
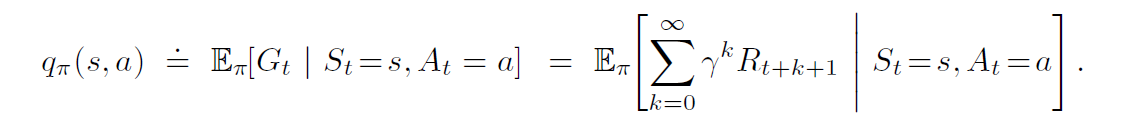
In order to solve this, we use the Bellman equation,

Once we have computed the value of each action, we can intuitively select the action with the highest value, because that action will result in the highest total reward in the long-run. Therefore, an optimal policy would always suggest the action with the highest qπ value.

As discussed above, an optimal value will always select an action that yields the highest long-term reward or in other words, the action that has the highest qπ value.
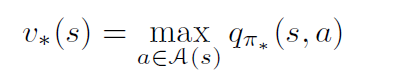
In conclusion, the optimal policy will be related to the value functions as follows:
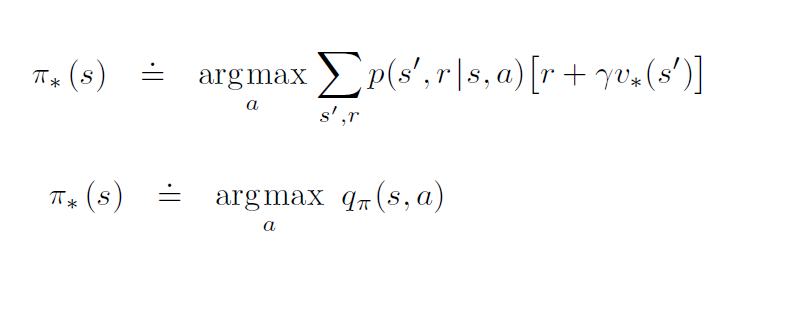
1. CS188 Introduction to Artificial Intelligence, UCB
2. Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.



Comments
Post a Comment