Markov Decision Processes Part 3: Bellman Equations and Optimal Policy
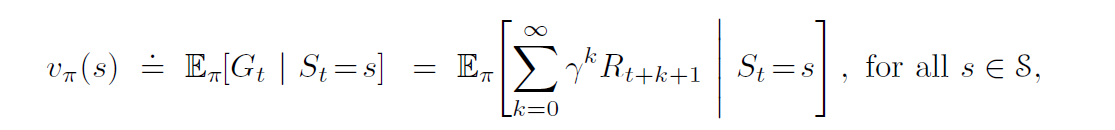
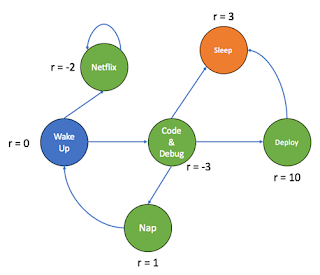
Since two posts we have been talking about MDPs. As discussed in the previous post, the ultimate goal of a MDP is to maximize the total future reward. In the last post, we had calculated the cumulative sum of the long-term rewards (G t ). In this post, we will calculate the expected long-term reward which the agent has to maximize. A value of a state is the total amount of reward an agent can expect to accumulate over the future, starting from that state. A value function computes the value of a state. A value of state gives us an estimate of how good the state is to be in. The value of a state should not be confused with rewards. A reward signal indicates what is good in an immediate sense, whereas a value function specifies what is good in the long run. For example, a state might always yield a low immediate reward but still have a high value because it is regularly followed by other states that yield high rewards. Since our goal is to maximise long-term reward, we take into acc...