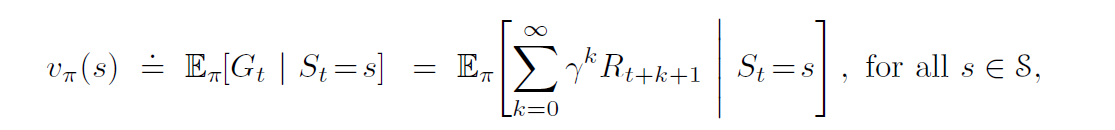Survey on using DeepRL for Quadruped Robot Locomotion

Legged robots are an attractive option to wheeled robots primarily for applications in rough terrain and difficult, cluttered environments. The freedom to choose contact points enables such robots to interact with the environment while avoiding obstacles effectively. With such capabilities, legged robots may be applied to application such as rescuing people in mountains and forests, climbing stairs, carrying payloads in construction sites, and inspecting unstructured under-ground tunnels. Designing dynamic and agile locomotion for such robots is a longstanding research problem because it is difficult to control an under-actuated robot performing highly dynamic motion that requires tricky balance. The recent advances in Deep Reinforcement Learning (DRL) has made it possible to learn robot locomotion policies from scratch without any human intervention. In this post, we discuss various research directions where DRL can be employed to solve locomotion problems in quadruped robots. Si...